Техническая реализация
Когда речь идет о том, что InfiniBand не использует общую шинную архитектуру, имеется в виду, что шина не используется в традиционном режиме разделения и блокировок (когда одно устройство захватывает шину, и до окончания операций с ней остальные ждут завершения обмена). Для этой технологии более приемлемой оказалась топология "логической шины" (switched fabric). Данное словосочетание можно перевести как "коммутируемая канва", но чаще (и неверно) оно переводится как "коммутируемая фабрика".
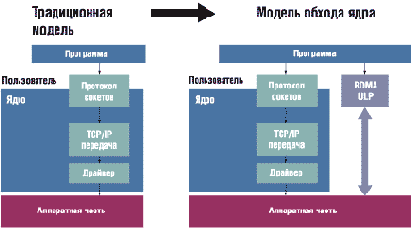
C RDMA вычислительный ресурс на одном сервере получает доступ к памяти программы
на удаленном сервере, не задействуя ядро процессора
Подобная топология ранее была известна также как FC-SW, где FC обозначает Fiber Channel, а SW - SWitch. Принцип осуществления коммутации в рамках этой топологии заключается в том, что каждый из узлов (серверов) связывается с каждым из хранилищ данных через группу коммутаторов.
Коммутаторы и подключения составляют один логический канал и называются "зоной". Когда серверу необходимо установить связь с конкретным хранилищем, он автоматически осуществляет поиск свободного коммутатора и начинает работать только с ним. Как следствие, отдельный канал не разделяется между несколькими передачами, а поскольку количество физических линий равно всем возможным соединениям, то передача всегда идет в полнодуплексном режиме.
Сами маршрутизаторы соединяются друг с другом специальной шиной Inter Switch Link (ISL) через E-port (E -Expansion). Очевидно, что две точки могут захватить более одного физического канала связи, так что скорость может наращиваться пропорционально наличию избыточных маршрутов.
Чтобы оценить суммарную скорость передачи, нужно принять во внимание следующие соображения. Один канал, используемый InfiniBand, изначально определен как последовательное экранированное соединение. В нем обеспечивается передача около 2,5 Гбит/с в каждом направлении. В зависимости от возможностей среды передачи InfiniBand может устанавливаться удвоенная и учетверенная скорость передачи, то есть 5 Гбит/с и 10 Гбит/с соответственно.
Поскольку каждый байт сопровождается двумя контрольными битами, реальная пропускная способность составляет 80% от номинальной, то есть могут формироваться потоки в 2 Гбит/с, 4 Гбит/с или 8 Гбит/с полезного трафика, причем обмен потоками происходит в полнодуплексном режиме.
Спецификация предусматривает объединение четырех или двенадцати каналов в один логический. В случае объединения двенадцати четырех скоростных физических каналов достигается номинальная скорость 120 Гбит/с (или 96 Гбит/с полезного трафика).
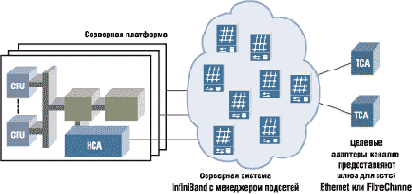
Технология InfiniBand предполагает использование множества узлов,
которые могут быть подключены в разных комбинациях
Такие величины, разумеется, нужно рассматривать только как теоретически определенные максимумы. Даже для критических приложений и конфигураций существуют "моменты отсечения", то есть пиковый трафик, на который не рассчитывают при проектировании пропускной способности. Можно сконфигурировать систему, способную пропускать любой трафик, но ее стоимость будет слишком высокой.
Особенно важным для межпроцессорного взаимодействия (IPC) параметром является время задержки, или латентность. Приемлемыми считаются значения не более 10 мс. Современные системы InfiniBand обеспечивают задержку до 4 мс. В других архитектурах, вроде локальной технологии AMD HyperTransport, применяющейся в кластерах Cray XD1, достигаются значения задержек до 1,5 мс. Но это достаточно специфическое и дорогое решение, которое к тому же не может массово использоваться в центрах обработки данных. В качестве естественного расширения Cray уже использует вариант "HyperTransport поверх InfiniBand", который скоро должен оформиться как отраслевой стандарт HyperTunnel.